비슷한 명령어 추천은 어떻게 하는걸까?
터미널에서 여러 프로그램을 사용하다 보면 종종 명령어를 잘못 입력해 프로그램이 오류를 표시해줄 때가 있다. 그런데 Git이나 npm 같은 일부 프로그램들은 내가 잘못 입력한 명령어와 비슷한 명령어들을 추천해주거나 오히려 오타를 바로잡아주고 알아서 적당히 넘어가 줄 때도 있다. 이런 기능은 대체 어떻게 작동할까? 이번 글에서는 비슷한 명령어를 추천해주는 기능을 비슷하게 구현해보며 그 원리를 알아본다.
git: 'comma' is not a git command. See 'git --help'.
The most similar command is
commit
----
npm@7.5.4
Did you mean this?
help
문제 정의하기
비슷한 명령어를 찾는다는 문제는 두 문자열의 유사도를 검사하는 문제로 치환할 수 있다. 예를 들어 사용자가 comma라는 문자열을 commit, fetch라는 두 문자열에 대해 유사도 검사를 한다면 commit이 더 comma와 유사하다고 판별될 것이다. 이런 식으로 사용자가 입력한 명령어를 프로그램에서 사용 가능한 명령어와 유사도 검사를 진행하고 최대한 비슷한 것들을 추려내 사용자에게 추천하면 기본적인 비슷한 명령어 추천 기능이 완성될 것이다.
편집 거리 (Edit distance)
문자열 유사도를 계산에는 보통 편집 거리 알고리즘을 사용한다. 편집 거리는 두 문자열이 있을 때 몇 번의 수정을 거쳐야 같은 문자열이 되는지 나타내는데 편집 거리가 짧을수록 최소한이 수정이 필요하므로 짧은 편집 거리를 가질수록 두 문자열이 유사하다는 것을 판별할 수 있다.
앞에서 설명했던 comma와 commit는 아래와 같이 총 2번의 수정이 필요하므로 편집 거리가 2라고 할 수 있다.
- 맨 뒤의
a를i로 변경 (comma->commi) - 문자열 끝에
t를 추가 (commi->commit)
이러한 편집 거리를 계산하는 알고리즘 중 비교적 널리 알려진 것이 해밍 거리와 최장 공통부분 수열(Longest Common Subsequence)이지만 두 알고리즘은 앞에서 정의한 문제를 해결하기에는 좋지 않다. 해밍 거리는 두 문자열의 길이가 같아야 사용할 수 있어 다양한 길이를 가진 문자열들을 비교하기에 부적합하며, 최장 공통부분 수열은 문자에 대한 삽입, 삭제 연산만 허용하기 때문이다. 그래서 이런 문제를 해결하는데 보통 레벤슈타인 거리(Levenshtein distance)를 사용한다.
레벤슈타인 거리 (Levenshtein distance)
레벤슈타인 거리는 한 문자열을 다른 문자열과 똑같이 만드는데 최소로 필요한 문자 삽입, 삭제, 변경 횟수를 나타낸다.
문자열 least와 cat을 가지고 예제를 통해 레벤슈타인 거리를 어떻게 구하는지 간단하게 알아보자. 거리를 구하기 위해 각 문자열의 길이 만큼의 크기를 가지는 2차원 배열을 만든다. 여기서 맨 앞의 ""는 공집합(빈 문자열)을 나타내는데 이 역시 이 문자열에 포함된다고 생각하자.
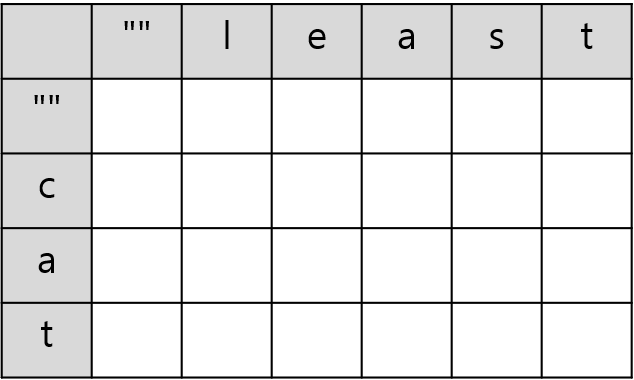
가장 먼저 공집합을 기준으로 레벤슈타인 거리를 계산한다. 그냥 단순히 인덱스에 맞춰 값을 채워 넣어주면 된다. 왜냐하면 예를 들어 빈 문자열 ""을 le로 만드는데에는 문자 2개를 추가하는 연산이 필요하기 때문이다.
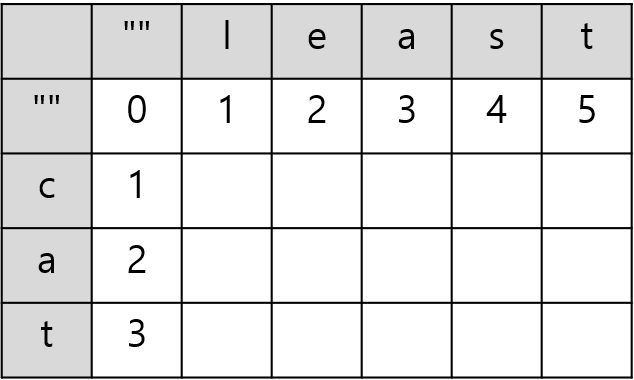
이제 2차원 배열을 순회하며 각 부분 문자열에 대한 레벤슈타인 거리를 구한다. 거리를 구할 때는 아래의 값 중 최솟값을 넣어주면 된다.
현재 levenshtein(i, j)의 값을 구하려고 할 때 아래의 값 중 최솟값을 사용한다:
levenshtein(i - 1, j) + 1: 문자를 삭제하는 경우 - 주황색levenshtein(i, j - 1) + 1: 문자를 추가하는 경우 - 파란색- 각 문자열을 A, B라 했을 때
- A의 i번째 문자와 B의 j번째 문자가 같다면
levenshtein(i - 1, j - 1): 아무 연산도 필요 없는 경우 - 초록색
- 다르다면
levenshtein(i - 1, j - 1) + 1: 문자를 변경하는 경우 - 초록색
- A의 i번째 문자와 B의 j번째 문자가 같다면
위의 알고리즘을 타입스크립트로 작성한 코드는 아래와 같다.
function levenshtein(source: string, target: string): number {
// (source.length + 1)x(target.length + 1) 크기의 2차원 배열 생성
const dist = [...Array(source.length + 1)].map(() => Array(target.length + 1));
// 공집합에 대한 거리 계산
for (let i = 0; i <= source.length; ++i) {
dist[i][0] = i;
}
for (let i = 0; i <= target.length; ++i) {
dist[0][i] = i;
}
// 문자열에 대한 레벤슈타인 거리 계산
for (let i = 1; i <= source.length; ++i) {
for (let j = 1; j <= target.length; ++j) {
const substitutionCost = Number(source[i - 1] !== target[j - 1]); // 문자 변경에 필요한 연산 횟수. 두 문자가 같다면 0이다.
dist[i][j] = Math.min(
dist[i - 1][j] + 1, // 문자를 삭제하는 경우
dist[i][j - 1] + 1, // 문자를 삽입하는 경우
dist[i - 1][j - 1] + substitutionCost, // 문자를 변경하는 경우
);
}
}
return dist[source.length][target.length];
}function levenshtein(source: string, target: string): number {
// (source.length + 1)x(target.length + 1) 크기의 2차원 배열 생성
const dist = [...Array(source.length + 1)].map(() => Array(target.length + 1));
// 공집합에 대한 거리 계산
for (let i = 0; i <= source.length; ++i) {
dist[i][0] = i;
}
for (let i = 0; i <= target.length; ++i) {
dist[0][i] = i;
}
// 문자열에 대한 레벤슈타인 거리 계산
for (let i = 1; i <= source.length; ++i) {
for (let j = 1; j <= target.length; ++j) {
const substitutionCost = Number(source[i - 1] !== target[j - 1]); // 문자 변경에 필요한 연산 횟수. 두 문자가 같다면 0이다.
dist[i][j] = Math.min(
dist[i - 1][j] + 1, // 문자를 삭제하는 경우
dist[i][j - 1] + 1, // 문자를 삽입하는 경우
dist[i - 1][j - 1] + substitutionCost, // 문자를 변경하는 경우
);
}
}
return dist[source.length][target.length];
}문제 해결하기
위 코드를 기반으로 명령어 추천 기능을 만들어보자.
먼저 적당한 명령어 집합을 만들자. 여기서는 생각나는 대로 적당히 적어놓은 아래의 git 명령어들을 사용한다.
const available_commands = [
"add",
"am",
"bisect",
"branch",
"checkout",
"cherry-pick",
"clean",
"commit",
"diff",
"fsck",
"init",
"mv",
"push",
"rebase",
"reset",
"restore",
"revert",
"rm",
"show",
"sparse-checkout",
"stage",
"stash",
"status",
"svn",
"switch",
"tag",
]const available_commands = [
"add",
"am",
"bisect",
"branch",
"checkout",
"cherry-pick",
"clean",
"commit",
"diff",
"fsck",
"init",
"mv",
"push",
"rebase",
"reset",
"restore",
"revert",
"rm",
"show",
"sparse-checkout",
"stage",
"stash",
"status",
"svn",
"switch",
"tag",
]앞에서 작성한 레벤슈타인 거리 함수를 이용하여 잘못된 명령어와 사용 가능한 명령어들을 비교해 비슷한 명령어들을 반환해주는 함수를 작성한다.
function didYouMean(command: string, commands: string[], limit: number = 5): string[] {
const candidates: {value: string, dist: number}[] = [];
let minDist = Infinity;
// 모든 명령어에 대해 레벤슈타인 거리를 계산하고, 최소 거리를 저장해둔다.
for (const candidate of commands) {
const dist = levenshtein(command, candidate);
candidates.push({
dist,
value: candidate,
});
minDist = Math.min(minDist, dist);
}
// 거리 오름차순으로 명령어 후보들을 정렬한다.
candidates.sort((a, b) => a.dist - b.dist);
// 그 후 거리가 최소 거리 + 2 이하인 명령어들만 골라내어 반환한다.
// + 2는 추천 범위를 넓히기 위해 넣었다.
return candidates.filter((item) => item.dist <= minDist + 2).slice(0, limit).map((item) => item.value);
}function didYouMean(command: string, commands: string[], limit: number = 5): string[] {
const candidates: {value: string, dist: number}[] = [];
let minDist = Infinity;
// 모든 명령어에 대해 레벤슈타인 거리를 계산하고, 최소 거리를 저장해둔다.
for (const candidate of commands) {
const dist = levenshtein(command, candidate);
candidates.push({
dist,
value: candidate,
});
minDist = Math.min(minDist, dist);
}
// 거리 오름차순으로 명령어 후보들을 정렬한다.
candidates.sort((a, b) => a.dist - b.dist);
// 그 후 거리가 최소 거리 + 2 이하인 명령어들만 골라내어 반환한다.
// + 2는 추천 범위를 넓히기 위해 넣었다.
return candidates.filter((item) => item.dist <= minDist + 2).slice(0, limit).map((item) => item.value);
}이제 위의 함수를 이용하여 비슷한 명령어를 찾아보자.
console.log(didYouMean('st', available_commands));
> ["am", "mv", "rm", "svn"]console.log(didYouMean('st', available_commands));
> ["am", "mv", "rm", "svn"]잘 찾아지는 것 같지 않다. 하지만 분명히 알고리즘으로 찾은 명령어들은 편집 거리가 2인 명령어들이다. 사실 이 문제는 조금 생각하면 쉽게 고칠 수 있다. 편집 거리와 찾은 명령어의 길이가 같다면 완전히 다른 문자로만 이루어졌다는 뜻이 된다. 그러므로 이러한 부분을 좀 수정해보자.
이제 편집 거리가 작더라도 완전히 다른 문자로만 이루어진 명령어는 나오지 않을 것이다.
...
for (const candidate of commands) {
let dist = levenshtein(command, candidate);
if (candidate.length === dist) {
dist = Infinity;
}
......
for (const candidate of commands) {
let dist = levenshtein(command, candidate);
if (candidate.length === dist) {
dist = Infinity;
}
...다시 해보니 전보다는 낫지만, 아직 불만족스럽다. 사용자가 st를 입력했다면 stage, stash, status 같은 더 유사한 명령어들을 추천해주는 것이 더 직관적이라 보이는데, 명령어 리스트에서 앞에 있으며 같은 편집 거리를 가진 명령어들이 나온다. 이 문제도 해결해보자.
console.log(didYouMean('st', available_commands));
> ["svn", "fsck", "init", "push", "reset"]console.log(didYouMean('st', available_commands));
> ["svn", "fsck", "init", "push", "reset"]가장 단순하고 직관적인 방법은 사용자가 입력한 문자열로 시작하는 명령어들에게 편집 거리를 아주 좋게 보이도록 변경하는 것이다. didYouMean 함수는 일반적으로 사용자가 입력한 문자열과 일치하는 명령어가 없는 경우에 호출될 것이니 편집 거리를 0으로 할당해도 별다른 문제가 없을 것이다.
if (candidate.length === dist) {
dist = Infinity;
}
if (candidate.startsWith(command)) {
dist = 0;
}
...if (candidate.length === dist) {
dist = Infinity;
}
if (candidate.startsWith(command)) {
dist = 0;
}
...다시 해보니 원했던 결과가 나온다.
console.log(didYouMean('st', available_commands));
> ["stage", "stash", "status", "svn"]console.log(didYouMean('st', available_commands));
> ["stage", "stash", "status", "svn"]이렇게 비슷한 명령어를 추천해 주는 기능을 비슷하게 구현해보며, 어떻게 동작하고 (완전히 같지는 않더라도) 어떻게 최적화해서 원하는 결과를 이끌어내는지 경험할 수 있었다.